In-Depth
Seven Principles of Effective RFID Data Management (Part 2 of 2)
In the second article of our two-part series, we look at four additional principles to help you effectively manage your RFID data.
In last week's article we examined three principles for helping deal with the vast and ever-changing data created by Radio Frequency Identification technology: digesting data close to the source, utilizing complex event-processing concepts, and employing RFID data concentrators.
Here are four additional principles to guide you to effective management of your RFID data.
Principle #4: Cache Context
Most RFID data is simple. Unless you’re using sophisticated, expensive tags, all you get is a serial number for the item, a time, and a location. Determining complex events from simple RFID event data requires context, and context typically comes from external data.
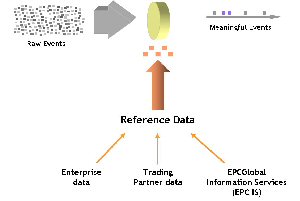 |
|
An example of context is the information about a trading partner found in an advanced shipping notice (ASN). As provided by a manufacturing plant, the ASN can be used to confirm that tagged items sent by the manufacturer were actually received. Context may also come from an EPC Information Services directory (EPC IS). EPCGlobal standards efforts may establish the EPC IS as global repository for trading partners to exchange detailed product information. The EPC IS allows anyone with proper authorization in Kellogg’s supply chain to learn that the EPC tag 01.0000A89.00016F.000169DC0 is actually a 24 ounce box of Kellogg’s Corn Flakes, and to know where it came from, where it’s going, when it was produced, and so on. Context data may also come from internal enterprise systems. For example, RFID-enabled baggage handling systems use data from passenger information systems to ensure that RFID-tagged bags get on the same plane you do.
Just as principle number 3 ("Employ RFID Data Concentrators") leverages in-memory data caching for event data, context data needs the same approach. EPCGlobal’s next generation (Gen2) standard of RFID readers specifies read rates of 1,800 a second, which means a distribution center with 20 readers could generate 36,000 events a second at peak rates. Adding 36,000 SQL requests to your existing warehouse database probably isn’t feasible, so it’s best to replicate, and cache this data in your data concentrator.
By caching context data in memory, your data concentrator can process RFID event data effectively.
Principle #5: Federate Data Distribution in Near Real Time
Our first of seven principles advocates processing data close to the source to manage complexity and protect central IT systems. But the items you’re tracking won’t stay put for long. For example, an RFID baggage tracking system must distribute data about your bags to your destination airport far in advance of your arrival. And since most operations are distributed, you must plan to distribute RFID data, in near real time.
The definition of federated, from Merriam-Webster, is: “united in an alliance.” Federating data is hardly new -- trading systems federate data daily among different financial centers and do it in near real-time. For RFID, federated data distribution unites the RFID data concentrators in an alliance -- whereby meaningful RFID events and context data is shared among members. A reliable, distributed middleware fabric facilitates data federation, integrated with the data caches at each concentrator, thus enabling meaningful events to be distributed among concentrators.
The implementation details of this near-real-time distribution fabric is beyond the scope of this article, but the principles are the same as we’ve described: process data close to the source, utilize data concentrators, cache data in concentrators, filter and handle exceptions. Ultimately, one must forward meaningful events to members of a distributed “alliance” to enable as close to a real-time view of the system as possible.
Federate data distribution so your RFID system can scale globally and as close to real time as possible.
Principle #6: Continuously Filter RFID Event Data
Even if you’re Wal-Mart, you probably won’t be adding seven terabytes of disk capacity daily to accommodate your RFID data. By continuously filtering RFID event data, you can reduce your working set, augment event data appropriately, and reduce load on down-stream systems, all at the same time.
An airline baggage handling system must track events from the gate to the plane, but they don’t all have to be stored forever. Yet RFID-enabled systems must permit operators to see the end-to-end baggage flow. The value is in understanding the baggage origin, how long it was on the conveyor belt, where it was handled, and how long it was handled. Furthermore, the basic flow information will need augmentation -- for example, at what time was the bag loaded into the aircraft and which cargo bay was it placed in?
Finally, performance and scalability typically requires that the storage of these events be optimized as the system runs. Successive filtering can delete events that are superfluous (e.g., redundant reads of baggage), supplement events that require context (e.g., associate a cargo bay number to a “bag loaded” event), siphon data off to other systems (e.g., save all baggage events for security subsequent security audits), and prepare event data to be distributed to other airports. At every step of the filtering process, the data concentrator’s cache (principle 3) must be kept transactionally consistent to provide system recoverability.
Successively filter data to keep your working set of data manageable, enrich raw data with required context, and reduce the load for down-stream systems.
Principle #7: Automate Exception Handling
Exception handling is the primary job of any RFID system. Exceptions include a bride at a wedding who gets cold feet and doesn’t show up at the church, or an airline baggage handling system that needs to take a bag off the plane that’s already been loaded. Today, people handle these exceptions. The maid of honor searches for the bride; the baggage handlers search for and retrieve bags by hand. In RFID-enabled systems of the future, your software must both detect exceptions and then automate exception handling.
Though complex event processing does detect events, exception handling requires knowledge of what happened leading up to this event. That operation requires an algorithmic approach to corrective action. The combination of CEP and event replay is what makes exception handling possible.
Event replay requires the storage of RFID events in a data cache that operates much like a TiVo for your RFID data. Just as TiVo has revolutionized the way we watch television, with flexible archival and random playback capability, RFID event replay can help automate exception handling. When an exceptional event occurs (e.g., bag must be reloaded), the data cache can replay the events for a particular item to figure out where it was last seen, which operator is physically closest to the item now, and then send a message, for example, to that person’s pager.
Without event replay, the RFID system has no ability to go back in time to discover when a bag was loaded, which section of the plane it was loaded into, and what to do to correct the exception.
Automate exception handling -- our final principle of effective RFID data management.
Pulling It All Together
Mature RFID deployments will change the face of enterprise IT by making real time data processing commonplace. This shift in computing style requires data management near the source of the data, context caching, RFID data concentrators, CEP, data federation, and event replay capability, all in an effort to making data processing real time and accurate. Adhering to these principles ensures you’re ready to tackle the challenges, and exploit the opportunities, that RFID presents. RFID may be relatively new to the “masses”, but there are current day examples to illustrate how to be successful -- and principles that can guide the way.