In-Depth
Harvesting Business Rules in a Process Context
Harvesting business rules from a legacy application has benefits ranging from simple documentation to application modernization. We provide a practical approach for collecting rules in a process context.
Harvesting business rules from a legacy application has many benefits, from simple documentation to application modernization. Most approaches to business rule mining recover rules from the code in a bottom-up fashion. This creates difficulties in classifying and understanding the context in which the rules are used. This article suggests a practical approach for collecting rules in a process context. Process information is collected top-down, rules are collected bottom-up, but there is a way to connect processes and rules such that the analyst can create a better picture of the business functions of the application.
Why Collect Business Rules from an Existing Application?
Harvesting business rules from a legacy application has many benefits. In the code of a traditional legacy application, the business and technical aspects are in most cases mixed together in a way that makes it very hard to distinguish the technical mechanisms from the implementation of the company’s business rules and processes. Collecting the real business rules in a methodical and (if possible) exhaustive manner will render multiple advantages:
- Business rules may simply serve as documentation of the application, useful both for those who maintain the application and for the end-users.
In a more complex scenario, business rules collected in a well-organized repository may serve as a means of communication between the IT people and the end-users. For example, if the rule repository has accurate information on the location of the rule implementation in the code, the developers may quickly locate the code that would be impacted by a rule change requested by business users.
The collection of business rules is also useful if the application is implemented in a new environment. The rules serve as documentation as well as a checklist, ensuring that no rules are left behind.
Classification of Rules
Understanding the benefits is half the equation. The other half is being able to efficiently and accurately mine the application rules. Several approaches exist, from user interviews to automatic mining from the code. A key point of rule mining is proper classification of the resulting rules. Absent such a classification, the rules will sit in an amorphous collection of little use.
Classification may be defined across many independent dimensions, including validation vs. computation, client vs. server, or simple vs. compound rules. One problem with these classifications is they do not answer a basic question: which are the business circumstances in which a rule is invoked? In other words, we need to know the relationships between individual rules and the processes of the enterprise.
To address this issue, we’ll look first at the common ways in which rules are collected.
Mining Approaches
Rule mining may proceed in a manual or automatic fashion, each method having advantages and disadvantages.
In an automatic approach, a specialized rule-harvesting software tool queries the application code and attempts to locate the fragments of code that implement business rules. This is quite a tricky process, as sometimes it’s hard to create a clear demarcation between the “business rule code” and code that simply creates the environmental mechanisms needed for the program to execute correctly. As the two may be easily confused, it is possible to obtain a large number of false positives (code that is mistakenly designated as a business rule implementation) as well as to miss important rules.
To overcome this weakness, use flexible search criteria which can be manipulated by an analyst while reflecting particulars of the application. For example, the analyst may notice that in a particular application all input validation rules reside in paragraphs or routines that contain the string “-EDIT-” thus providing a good search criteria.
Searches through application code cannot be simply text-based. Ideally, to zero-in on the business rules implementation code requires more sophisticated searches based on the particular grammar of the language of the code. The examples below illustrate the power of such syntax-based queries, in a COBOL/CICS program:
Screen validations: This query helps find all tests against variables that receive values from a screen (see Figure 1).

Figure 1
Validating an item type: This query finds all tests that have as a result the invocation of a program that displays all available item types (see Figure 2).

Figure 2
In a manual approach, all stakeholders of the application may be interviewed and solicited to list and explain the rules of which they are aware. Rules may also be collected from existing documentation or from other sources.
Manual and automatic methods for rule mining each have their advantages and disadvantages, as described in the table below:
| Advantages | Disadvantages | | Manual | Rules are expressed in a clear business language. Rules not enforced by the application also are discovered, opening the opportunity to improve the application. | Rules implemented in the code may be missed. There is no information about the actual location of a rule’s implementation. Rule collection process is long, costly and inefficient. |
| Automatic | Implementation code of each rule is identified and recorded. Rule collection is fast and efficient. | False positives -- some technical mechanisms are mistakenly identified as rules. Missing rules – in case the search criteria are not refined or sophisticated enough. Clear business description of rules cannot be automatically determined. |
As the two methods complement each other, it is natural that some combination of the two is the best strategy. In such an approach, an automatic mining is performed first, followed by a manual review, refinement, and additional specification. Using both methods ensures that false positives are removed and the rules are properly documented with references to actual implementation in the code.
While some degree of automation is necessary to make a rule harvest cost efficient and practical, rules are collected without a clear process context. The analyst may discover a rule that declares “a 10 percent discount is given for all orders over $100,” but there is little or no knowledge about the circumstances in which the rule comes into play. Such “circumstances” are best described as use cases or activities that could be specified (for instance, in UML diagrams). In the next section, we will discuss how the two approaches can be united to form a complete “top-down” and “bottom-up” approach to understand an organization’s processes.
Process -- Rule Symmetry
In the first section of this paper, we determined that there is a significant value to be gained from combining a “top-down” process-centric view with a “bottom-up” rules-centric view. We turn our attention now to the combination of these views.
Notice the symmetry between business rules and processes. Business rules are declarative (e.g., “customer must be over 18”); process diagrams are prescriptive (e.g., “receive payment, then send order”). Business rules are implemented in relatively short fragments of code; processes are implemented through a series of programs and user interfaces. For all these reasons, it is natural that processes are collected “top-down” while rules are collected “bottom-up.” An analyst would start by describing the main use cases and then detail them in activity diagrams. On the other hand, business rules are discovered at a lower level as detailed policy implementations.
| Processes | Business Rules | | Nature | Prescriptive | Declarative |
| Implementation | In execution flows | In fragments of code |
| Discovery | Top-down | Bottom-up |
Just as business rules may be harvested from the application code following a particular methodology, processes may be harvested from the application in a similar fashion. The approach that would render the most complete picture is one in which the analyst looks at the existing application artifacts and combines that knowledge with descriptions obtained from the application stakeholders. The benefit of code analysis (manual or with the aid of automation) is that discovered processes may always be related back to the code artifacts that implement them.
Connecting Processes and Rules
The symmetry between processes and rules gives us a picture that begs for a linkage between the two aspects of the application. The linkage between these two provides additional information about both the business processes and the application that implements them (see Figure 3).
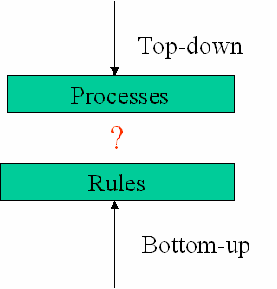
Figure 3
We can formulate this linkage in these terms:
Rather than a simple activity diagram or a flat collection of business rules, one would wish to see a diagram more like Figure 4:
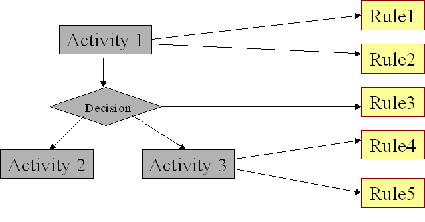
Figure 4
Both the process modeler and the business rules modeler would benefit by this link.
The process analyst would be able to answer the question: “What are the important details of the implementation of this process?”
The business rules analyst would be able to answer the question: “When is this rule used?”
| Note on Modeling |
| While standard UML allows for specification of business rules as part of the textual attributes of use cases or activities, this type of modeling does not express the full power of linking process and rules. In particular, if the rule appears just as text inside a use case specification, it is impossible to describe “reuse,” i.e., the fact that the same rule may appear inside a number of use cases. At press time, OMG had started to look into possible linkage between SBVR (business rules model) on one side and BPM and UML on the other. |
Harvesting Rules in a Process Context
Harvesting business rules and processes from code makes the linkage between the two easier to accomplish. Each process and rule would have an attribute that describes its location in the code.
| Processes | | Process | Program | Lines | Activity
A1 | P1
P2 | 750-900
1200-1600 | Activity
A2 | P3 | 680-830 | | | Rules | | Business Rule | Program | Lines | | BR1 | P1 | 810-815 | | BR2 | P1 | 890-900 | | BR3 | P2 | 1320-1325 | |
Even if two separate teams harvest the processes and rules, it is now possible to link the two by programmatically joining the two tables. One may notice, for example, that the business rule BR1 is used in activity A1, because the code implementation of this business rule is included in the code implementation for the activity. In reality, such connections may be more complex, but a more complete model may be inferred, as in Figure 5:
Organizing a Rule-Harvesting Project
Harvesting business rules and processes from a legacy application may require various skills and as such, may involve multiple people or teams. Assuming that rule-harvesting and process-harvesting software is available, a project may be organized on the following lines:
- A “rule team” collects the rules; this activity may be broken into further steps:
- Criteria are specified for automatic rule collection
- Queries are run that would identify the rules based on the criteria
- Criteria are refined and the two steps above are repeated until a satisfactory set of rules is identified
Rules are documented, classified, and audited by people with in-depth knowledge of the business. A “process team” collects the processes. Processes could be expressed, for example, in use-case or activity diagrams. They are harvested from the code, but audited and confirmed by people with in-depth knowledge of the business. The two tracks above may run in parallel. When finished, rules and process are brought into a common repository or database where they are connected, as explained in the section above. If this is a modernization project, where a new implementation of the application is the final goal, then: - Process diagrams and definitions are handed over to the architects.
- Rules are handed over to the developers, who can now implement the processes using the rules as detailed specifications.
Such an approach results in a good functional specification of the application, and in a practical way of organizing a modernization project.
Summary
The business processes and rules of most organizations are tightly interwoven throughout millions of lines of highly complex code. This technical complexity is often combined with a decline in the level of subject-matter expertise related to business processes -- a natural byproduct of the aging of an application portfolio. As a result, organizations frequently lose their understanding of the structure and behavior of their core business processes. Without this insight, they cannot efficiently determine where modifications need to be made to their applications to ensure alignment with business needs -- hindering operational flexibility. By taking a combined “top-down” and “bottom-up” approach, the move towards increased flexibility is accelerated.