News
Study Shows Apache Spark Prominence in Big Data Analytics
The growing traction of the Apache Spark project in Big Data analytics was reaffirmed in a recent survey conducted by reactive programming specialist Typesafe.
Typesafe partnered with commercial Spark champion Databricks Inc. for the survey (registration required) of more than 2,100 developers and associates staffers. It revealed that some 13 percent of respondents currently used Spark in production, with 20 percent planning to use it in 2015 and 31 percent evaluating it.
Spark uses in-memory primitives and other enhanced technologies to outperform MapReduce and offer more computational options, with tool libraries for enhanced SQL querying, streaming data analytics, machine learning and more. The Spark project is recognized as the most active Apache Software Foundation and Big Data open source project.
The "hockey-stick-like growth" in Spark awareness and adoption revealed in the survey was confirmed by a Google Trends chart, the company said.
"The survey shows that 71 percent of respondents have at least evaluation or research experience with Spark -- 35 percent are using it or plan to adopt soon," Typesafe said in a new release. "Of the survey respondents running Big Data applications in production, 82 percent indicated that they are eager to replace MapReduce with Spark as the core processing engine."
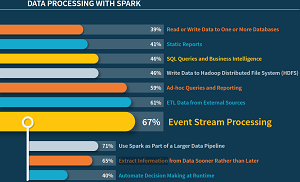 [Click on image for larger view.]
'How will you use Spark to process your data?' (source: Typesafe)
[Click on image for larger view.]
'How will you use Spark to process your data?' (source: Typesafe)
The big attraction of Spark is its faster data analysis and ability to handle event streaming, Typesafe said.
The big problems with Spark are lack of in-house experience, immaturity of some components and difficulty integrating with other middleware and management tools.
"The need to process Big Data faster has largely fueled the intense developer interest in Spark," said Typesafe exec Dr. Dean Wampler. "Hadoop's historic focus on batch processing of data was well supported by MapReduce, but there is an appetite for more flexible developer tools to support the larger market of 'mid-size' datasets and use cases that call for real-time processing."
Typesafe, which makes the Typesafe Reactive Platform for building modern apps and stewards the Scala programming language, said its interest in Spark was piqued by an earlier survey it conducted about the Java programming language. It found a surprising representation of Spark interest and decided to conduct a follow-up survey to further explore the issue.
Typesafe exec Jonas Bonér explained in a blog post.
"Back in summer of 2014, we launched the results of a survey on Java 8, which shared a lot of information we were looking for, but also contained a small golden nugget of data that we didn't expect: that out of more than 3,000 developers surveyed, a shocking 17 percent of them reported using Apache Spark in production," Bonér said. "Wait, Apache Spark? Yep. Apache. Spark."
That result probably wasn't so surprising to Databricks, which bases its business model on the commercial distribution of Spark along with associated services and support. The company was founded by veterans from the academic project that originally developed Spark.
"In total, the survey covers over 500 enterprises that are using or planning to use Spark in production environments ranging from on-premise Hadoop clusters to public clouds, with data sources including key-value stores, relational databases, streaming data and file systems," said Databricks exec Kavitha Mariappan in a blog post today. "Applications range from batch workloads to SQL queries, stream processing and machine learning, highlighting Spark's unique capability as a simple, unified platform for data processing."
Survey results indicated:
- The top technologies used for production infrastructure are Amazon EC2, Docker and Cloudera CDH.
- The top programming languages used with Spark are Scala, Java and Python.
- The top usage scenarios are running Spark standalone, with YARN and in Local Mode.
- The top ways to load Spark are from the Hadoop Distributed File System (HDFS), databases and Apache Kafka.
- The top features or modules in demand are the core API to replace MapReduce, the Streaming Library and the Machine Learning Library.
The survey report summed up its conclusion: "Developers have a pent-up need to eliminate issues with MapReduce, such as a difficult API, poor performance, and restriction to batch jobs only." Spark will fulfill that need, Typesafe said, but there is more work to be done.
"Spark is less mature than older technologies, like MapReduce, so developers also need good documentation, example applications, and guidance on runtime performance tuning, management and monitoring," the report summarized. "Spark is also driving interest in Scala, the language in which Spark is written, but developers and data scientists can also use Java, Python, and soon, R."
About the Author
David Ramel is an editor and writer at Converge 360.