In-Depth
Data Virtualization and NoSQL Data Stores
Big Data is increasing the popularity of NoSQL where SQL is not the primary processing language. The challenge: integrating disparate NoSQL systems.
By David Besemer, CTO, Composite Software, Inc.
If information is power, then data integration is its engine -- an engine fueled by diverse and ever-changing data sources.
One data integration approach, data virtualization, has over the past eight years expanded its adoption among enterprises and government agencies due to its ability to evolve rapidly and incorporate the latest IT innovations. Originally limited to relational sources and business intelligence (BI) consumers, data virtualization today supports a wide range of sources including multi-dimensional stores, Web and data services, XML documents, analytic appliances, on- and off-premises applications and more. NoSQL data stores are the newest source type supported by data virtualization.
NoSQL is a data store managing data that is not strictly tabular and relational. Beyond being non-relational, NoSQL data stores are typically distributed, open-source, and horizontally scalable, although there are exceptions for specific NoSQL data stores.
The main driver for the creation of NoSQL data stores has been the emergence of “Web-scale” data -- i.e., massive amounts of data -- at the large Web sites and services such as Amazon, Google, Yahoo!, Facebook, etc. Recently, predictive analytics, voice-of-the-customer, churn, fraud, and other “big data” use cases have emerged to further accelerate demand.
The NoSQL Data Stores Landscape
Although the original emergence of NoSQL data stores was motivated by Web-scale data, the movement has grown to encompass a wide variety of data stores that do not use SQL as their primary processing language. NoSQL data stores can be categorized as:
-- Tabular/Columnar Data Stores: Storing sparse tabular data, these stores look most like traditional tabular databases. Examples include Hadoop/HBase (Yahoo!), BigTable (Google), Hypertable, and VoltDB.
-- Document Stores: These sources store unstructured (e.g., text) or semi-structured (e.g., XML) documents. Examples include MongoDB, Mark Logic, and CouchDB.
-- Graph Databases: These NoSQL sources store graph-oriented data with nodes, edges and properties, and are commonly used to store associations in social networks. Examples include Neo4J, AllegroGraph, and FlockDB.
-- Key/Value Stores: These sources store simple key/value pairs like a traditional hash table. They are further subdivided into in-memory and disk-based solutions. This category of NoSQL systems probably has the largest number of members, each embodying slightly different characteristics. Examples include Memcached, Cassandra (Facebook), SimpleDB, Dynamo (Amazon), Voldemort (LinkedIn), and Kyoto Cabinet.
-- Object and Multi-value Databases: These types of stores preceded the NoSQL movement but they have found new life as part of the movement. Object databases store objects (as in object-oriented programming). Multi-value databases store tabular data, but individual cells can store multiple values. Examples include Objectivity, GemStone, and Unidata.
-- Miscellaneous Sources: Several other data stores can be classified as NoSQL stores, although they don’t fit into any of the categories above. Examples include GT.M, IBM Lotus/Domino, and the ISIS family.
Virtualizing NoSQL Data Store Sources
Data virtualization platforms provide a complete toolset for accessing, federating, abstracting, and delivering information from diverse sources. Access is typically done via standards-based protocols and APIs; for example, JDBC and ODBC for SQL-based sources, HTTP and SOAP for Web services, JMS for messages, and APIs for enterprise and cloud-based applications. Through these methods, source data is securely exposed from a single virtual location, regardless of how and where it is physically stored. (See Figure 1.)
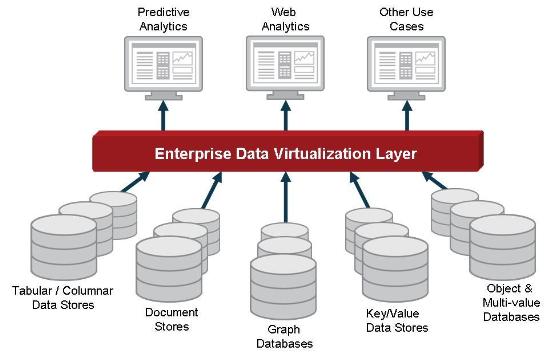
Figure 1
Although NoSQL access standards have yet to develop fully, each implementation provides a Java-based development API appropriate for accessing that type of NoSQL data. Data virtualization platforms typically use these APIs to access and integrate data. Three kinds of NoSQL systems are particularly suited for the data virtualization platform: tabular/columnar data, XML documents, and key-value stores.
How to Integrate Tabular/Columnar Data Stores
Because data virtualization platforms were originally designed for tabular data, retrieving and processing data from this category is a natural fit. The preferred data retrieval paradigm for tabular/columnar data stores leverages “table functions” in the FROM clause of a SQL statement. That is, a procedure resource that returns a cursor can be dropped into the data virtualization development environment as a table, where it will show up in the FROM clause of the SQL statement.
Tabular/columnar NoSQL data sources typically store very large data sets. Table function implementations should ensure sufficient data reduction within the source by leveraging input parameters. Also, the processing of large data sets can take a long time, so some form of caching may be prudent to retain the results for reuse.
This approach provides full access to the data in the underlying NoSQL source, and it will likely be sufficient for most near-term needs. However, more generic filtering and aggregation might be possible with the underlying NoSQL source, and purpose-built table functions provide only a limited interface to the data virtualization platform. If a particular NoSQL tabular data store becomes quite popular, expect data virtualization platform providers to develop a custom adapter that more fully integrates and leverages that data source’s specific capabilities.
How to Integrate XML Document Stores
Because XML document store sources leverage XQuery as their preferred data retrieval paradigm, data virtualization platforms with embedded XQuery engines (and XML as a native data type) can easily retrieve and further process documents from this category of NoSQL data store.
For a specific NoSQL XML document store, a minimum of two custom procedures can be implemented that leverage the NoSQL system’s Java API. Both procedures would return an XML document that can be further manipulated by any of the upstream XML manipulation functionality (e.g., XSLT transformations). The first procedure takes a document handle (unique identifier) as its input argument and leverages the API to retrieve and return that document. The second procedure takes an XQuery specification as its input argument and leverages the API to execute the query and return the results as a single document. Of course, additional procedures accepting more specific parameters could also be implemented, making integration into multiple views easier.
How to Integrate Key/Value Stores
Data virtualization platforms can integrate key/value stores in two ways. The first is as a simple custom SQL function. This function can be created so that it takes the key as a parameter and returns the value. This common function can then be used in SQL statements throughout the data virtualization platform.
The second leverages an in-memory key/value store as a cache target. This approach is best for small data sets or procedure results; it doesn’t work very well for large tabular data sets. Further, this form of cache integration is often challenged by the impedance mismatch between cached tabular data and cached key/value data (the cached data is opaque inside the key/value store), so the entire set must be retrieved for processing.
The Last Word
NoSQL is increasingly being adopted with the expansion of “big data” use cases as well as other data stores where SQL is not the primary processing language. The challenge to enterprises is to integrate disparate NoSQL systems, each with its unique and non-standard API. Today’s evolved data virtualization platforms provide access to information from virtually any data store (with some minimal programming), using standard resources, and therefore are inherently suited to integrate NoSQL systems.
David Besemer is the CTO of Composite Software, Inc. You can contact the author at [email protected]