In-Depth
Seven Principles of Effective RFID Data Management (Part 1 of 2)
Instant decision-making on high-volume, high-velocity data streams isn't a new challenge. We examine seven principles to help manage RFID data.
Though the recent publicity might suggest differently, Radio-Frequency Identification technology (RFID)—the technology that uses radio waves to identify individual items for purposes of management and control—is not new. RFID first appeared during World War II when Allied aircraft carried transponders that would acknowledge radar interrogations from friendly aircraft. Since then, both the size and cost of RFID tags have followed the progression of Moore’s Law to where it’s now feasible to attach RFID tags to a package of razor blades. But in fact, RFID has been used in commercial applications for years, from automated toll systems like E-Z Pass to automated manufacturing facilities.
In 2003, triggered by mandates from Wal-Mart and others, a media feeding frenzy ensued. Such mandates have validated that RFID just might enable a new era of business optimization where a Proctor and Gamble can instantly know its inventory stock levels, a Gillette can eliminate razor blade theft, and a Wal-Mart can squeeze even more cost from its supply chain by reducing the labor associated with bar-code scanning. This value, accumulated millions of times daily, will add up to billions. And that’s just the beginning: visionaries see RFID impacting anything that involves physical items where keeping track has value: baggage tracked by airlines to improve security; Alzheimer’s patients monitored in real time; pharmaceutical shipments to curtail counterfeiting.
But every opportunity carries its challenge, and there are many challenges posed by RFID. One of the biggest hills to climb is dealing with the flood of data RFID generates: in-store RFID implementation at Wal-Mart will generate as much data in three days as is contained in the entire U.S. Library of Congress (based on estimates from analyst Jim Crawford from Retail Forward). And it’s not just a problem for companies the size of Wal-Mart—even modest RFID deployments will generate gigabytes of data a day. To make matters worse, the data changes quickly, so approaching RFID by trying to handle the data volumes in large batches won’t work. The volume and velocity of RFID data place too heavy a burden on existing technology infrastructure.
Capturing large volumes of data at high velocity is just the first step. Woody Allen once said: “I took a course in speed reading and was able to read War and Peace in 20 minutes. It's about Russia.” If all you learn from massive volumes of RFID data is the most general conclusions, then the value of that data is lost. It is as if one looked at a 250-gigabyte disk drive filled with useful information and concluded simply that it contained 10,424 files. If all you do is capture RFID events, then most of the value is lost because the advantage of RFID is real time knowledge, not data collection.
Instant decision-making on high-volume, high-velocity data streams is not a new challenge. It is the same problem found in the program-trading systems of large investment banks, the command and control applications used by the military, and the network management applications in telecommunications. Based on experience in those industries, as well as RFID system development, I pose seven principles to help you effectively manage your RFID data.
Principle #1: Digest the Data Close to the Source
You could water your lawn pretty quickly if you used the fire hydrant on your street. But hooking your garden hose directly to the hydrant will only serve to get you a hose blown apart, a big pool of water and a very angry fire chief. Try to deploy an RFID system by directly connecting RFID readers to your central IT systems and the results will be similarly disastrous.
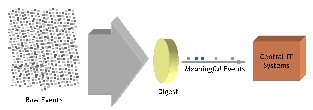 |
|
Digest your RFID event traffic close to the source—at the “edge” of the enterprise - and forward only the meaningful events to central IT systems. And the digestion process is more than basic filtering—it’s data cleansing, consolidation, and summarization; it’s exception handling of many types—automated and human-made; it’s compensation for unreliable technical infrastructure—application, hardware, network failure; it’s adjustment for unreliable RFID tag-reader environments. Digestion of data close to the sources allows this complex processing to occur, and allows exceptions to be handled locally, protecting central IT systems from the flood of data.
So, digest RFID event data close to the source of RFID activity.
Principle #2: Utilize Complex Event-Processing Concepts
Complex Event Processing (CEP) is a new field that deals with processing multiple streams of simple events. The goal: to identify the complex events within those streams. Examples of simple events include a church bell ringing, the appearance of a man in a tuxedo, and rice flying through the air. A complex event is what one infers from the simple events: a wedding is happening. CEP helps discover complex, inferred events by analyzing the events: the bells, the man in a tux, and the rice flying through the air.
 |
|
CEP has been pioneered by David Luckham, a professor at Stanford University and the author of "The Power of Events, An Introduction to Complex Event Processing in Distributed Enterprise Systems." In his book, Luckham defines a complex event query language that treats event time and order, in addition to event data, as the basic elements of data processing. According to Gartner, CEP will become a common computing model within five to ten years. But developers aren’t sitting still - you can build CEP systems today in languages like Java or C++.
Whether you use a CEP tool or build your own, principle #2 is: use the concepts of CEP for RFID.
Principle #3: Employ RFID Data Concentrators
You could water your lawn using water from a hydrant if you could step down the pressure and flow. One way to deal with the gush of RFID data is to develop RFID data “concentrators” that help control the flow of RFID event streams.
An RFID data concentrator is software that collects and processes raw RFID event flows close to the source of the data (principle 1). There are three primary elements: RFID middleware, event processing, and an in-memory data cache.
RFID middleware provides a hardware-independent interface that enables RFID readers to be interrogated. There are many commercial implementations of RFID middleware already, including the EPCGlobal’s ALE standard. EPCGlobal is the worldwide RFID standardization organization. Its ALE (Application Level Event) standard defines this application-to-hardware interface.
Event processing handles high-volume, high-performance flows of events by organizing raw events into pipelines. Pipelining is a concept found in hardware and software systems of many types, including the central processing units (CPUs) in your computer, in software designed for handling stock market feeds in real time, and transaction processing systems that your credit card company uses. Pipelines allow the events to be grouped, then processes those groups with a set of simple tasks, as each thread gets a slice of processing time from the CPU. By performing a large number of operations on data in small “bursts”, overall throughput is increased, and the average speed that any individual event can be processed is increased, as well.
Finally, an in-memory database, or data cache, makes the concentrator work in real time. In-memory data management techniques are crucial to accommodate the real-time nature of RFID. It’s a basic law of physics: memory is 1,000 times faster than disk. Physics is the reason why MIT’s Auto-ID center included a “Real Time In-Memory Event Database,” or REID, as part of its first RFID reference architecture. Similarly, Stanford’s CEP research has employed an “in-core-memory” database. While this cache provides much the same reliability, availability, and fault tolerance of a database, the distinction of calling this element a “cache” is to distinguish it from the enterprise application database, shown at right in the data concentrator diagram.
Employ data concentrators that combine RFID middleware, event processing, and an in-memory data cache to achieve the reliable speed you need.
Four More Principles
Mature RFID deployments will change the face of enterprise IT by making real time data processing commonplace. In this article we explained the first three of six principles to effectively navigate the new challenges RFID deployments will face in terms of the volume, velocity, and analysis of data. Next week I’ll discuss the next four principles, and tie all the principles together.