In-Depth
Seven Deadly Sins of Database Design
How to avoid the worst problems in database design.
by Jason Tiret
Several factors can lead to a poor database design -- lack of experience, a shortage of the necessary skills, tight timelines and insufficient resources can all contribute. In turn, poor database design leads to many problems down the line, such as sub-par performance, the inability to make changes to accommodate new features, and low-quality data that can cost both time and money as the application evolves.
I constantly hear from data professionals that if you don’t get the data right, nothing else matters. However, many times it is the tail (i.e., the application) that’s wagging the dog rather than the dog wagging the tail. The database just comes along for the ride as the application grows in scope and functionality.
Addressing some simple data modeling and design fundamentals can greatly alleviate most, if not all, of these concerns. In this article we’ll focus on seven common database design “sins” that can be easily avoided and suggest ways to correct them in future projects:
- Poor or missing documentation for database(s) in production
- Little or no normalization
- Not treating the data model like a living, breathing organism
- Improper storage of reference data
- Not using foreign keys or check constraints
- Not using domains and naming standards
- Not choosing primary keys properly
Sin #1: Poor or missing documentation for database(s) in production
Documentation for databases usually falls into three categories: incomplete, inaccurate, or none at all. To make matters worse, it is almost never centralized in one place. Without proper, centralized documentation, understanding the impact of a change is difficult at best, impossible at worst. This causes developers, DBAs, architects, and business analysts to scramble to get on the same page. They are left up to their own imagination to interpret the meaning and usage of the data.
Additionally, developers may think that the table and column names are descriptive or self explanatory enough to understand the usage of the data (more on this with Sin #6). However, as the workforce turns over, if there is no documentation in place, knowledge of the systems can literally walk out the door leaving a huge void that is impossible to fill. Even starting bottom-up with just the physical information can alleviate the issue of lack of documentation tremendously.
The best approach is to place the models into a central repository and spawn automated reports because despite minimal effort everyone benefits. Producing a central store of models is only half the battle, though. Once that is done, executing validation and quality metrics will enhance the quality of the models over time. As your level of governance increases, you can extend what metadata is captured in the models.
Sin #2: Little or no normalization
There are times to denormalize a database structure to achieve optimized performance, but sacrificing flexibility will paint you in a corner. Despite the long-held belief by developers, one table to store everything is not always optimal. The “one table” approach may make data access easier, but invariably there will be many NULLs for columns that do not apply to a record, and special application code will be needed to handle it. Another common mistake is repeating values stored in a table. This can greatly decrease flexibility and increase difficulty when updating the data.
Understanding even the basics of normalization adds flexibility to a design while reducing redundant data. The first three levels of normalization are usually sufficient for most cases:
- First Normal Form: Eliminate duplicate columns and repeating values in columns
- Second Normal Form: Remove redundant data that apply to multiple columns
- Third Normal Form: Each column of a table should be dependent on the primary identifier
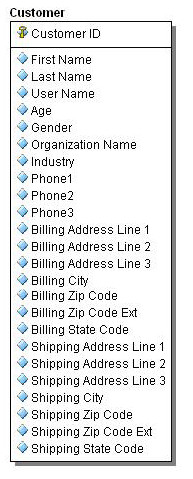
Figure 1: Denormalized structure
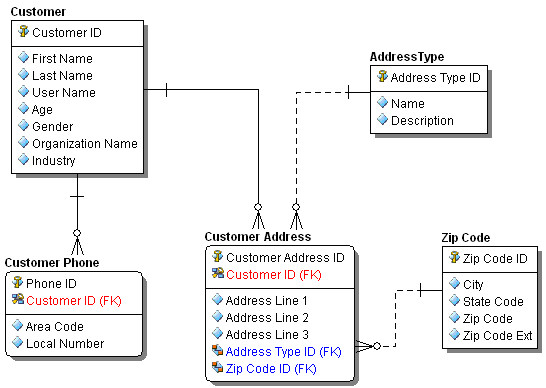
Figure 2: Normalized equivalent
The first normal form tells us to break off Address and Phone information into their own tables with identifiers. Following the second normal form, we break off Zip Code information into its own table so that it is not duplicated for each address. Consideration should be made for City and State information as well, but that might be a case where performance over duplication wins. Third normal form would have us look at Organization Name and Industry in the Customer table and put those into their own tables since they are not functionally dependent on the Customer ID. The same would apply to City and State Code in the ZIP Code table.
Sin #3: Not treating the data model like a living, breathing organism
I have seen numerous examples of customers performing the modeling up front, but once the design is in production, all modeling ceases. It is always preferable to design first then build. It is proven that errors corrected in the design phase are significantly less costly than those fixed after production.
The sin arises when changes creep into the database due to critical production issues. Inevitably, the model is then left languishing on the side if there is not a process to update the model along with the database. As more changes occur in the database, the model becomes useless.
Undocumented data can also lead to security and compliance risks, poor understanding of future changes and the inability to adapt to future needs of the business. Although the design-then-build practice may be a utopia that is never reached, the changes need to find their way back to the model.
Sin #4: Improper storage of reference data
I see two main problems with reference data. It is either stored in many places or, even worse, embedded in the application code. It is almost never captured in the data model with the rest of the documentation. This causes huge problems when a reference value needs to change. Reference values provide valuable documentation which should be communicated. Your best chance is often via the model. It may not be practical to store reference values in the data model if you have large volumes, but there is no excuse not to point to them from the model. The key is to have it defined in one place and used in other places.
Sin #5: Not using foreign keys or check constraints
I hear customers complain all the time about the lack of referential integrity (RI) or validation checks defined in the database when reverse engineering databases. For older database systems, it was thought that foreign keys and check constraints slowed performance, thus, the RI and checks should be done via the application. This might have been the case in the past, but DBMSs have come a long way.
The ramifications on data quality if the data is not validated properly by the application or by the database can be substantial. If it is possible to validate the data in the database, you are better off doing it there. Error handling will be drastically simplified and data quality will increase as a result.
Sin #6: Not using domains and naming standards
Domains and naming standards are probably two of the most important things you can incorporate into your modeling practices. Domains allow you to create reusable attributes so that the same attributes are not created in different places with different properties. It is extremely important to have a common set that everyone can use across all models. Naming standards allow you to clearly identify those attributes consistently.
Having a set of standards also ensures consistency across systems and promotes readability of models and code. You don’t want short, cryptic names that users need to interpret. Given the advanced nature of the latest vendor releases, the days of limited column length name are over when building new databases. Always have a common set of classwords to identify key types of data and use modifiers as needed.
Sin #7: Not choosing primary keys properly
I was once told by a senior data architect that “When choosing a primary key, you’d better get it right because changing it down the line will be a royal pain.” Sure enough, later I worked with a different customer who had the un-enviable chore of managing a migration project because a system used Social Security number as a primary key for individuals. They found out the hard way that SSNs are not always unique and not everyone has one.
The simplest principle to remember when picking a primary key is SUM: Static, Unique, Minimal. It is not necessary to delve into the whole natural vs. surrogate key debate; however, it is important to know that although surrogate keys may uniquely indentify the record, they do not always unique identify the data. There is a time and a place for both, and you can always create an alternate key for natural keys if a surrogate is used as the primary key.
Jason Tiret is the director of product management for modeling and design solutions for Embarcadero (www.embarcadero.com), a provider of multi-platform database tools and developer software.