In-Depth
Integrating Canonical Message Models and Enterprise Data Models (Part 2 of 3)
How an enterprise data model is used to "facilitate messaging" and the benefits of using it that way.
By Dr. Tom Johnston, Chief Scientist, Asserted Versioning, LLC
In the SOA paradigm, an enterprise data model (EDM) facilitates messaging. When a message is sent from a source to a target database, both a transport function and a mapping function are involved. The transport function moves the message from source to target. The mapping function translates between the different formats that source and target have for the same data.
If both source and target use the same format for the data in a message (and mean the same thing by it), then no mapping will be required, but in Part 1, we saw why this is generally not the case. Even when an enterprise has a canonical format for all its data, or at least for its most important data -- that canonical format being the one defined by the EDM -- it is unlikely that it will have re-engineered its major databases to be EDM-consistent. It just costs too much to do that.
Point-to-Point Messaging
Mapping messages from a source database to a target database incurs costs. There are the costs of writing and managing the code that does the mapping and of running that code every time a message requires it. If a source database sends the same message to n target databases, and if none of those databases formats the data in the same way the source database does, then n translations will be required. If a single format is used to mediate the data exchange, then the source database will only have to map from its proprietary format into the canonical format for the data in the message.
Conversely, if m source databases send the same message to a target database, and if none of those databases uses the same format for the data in the message, then m translations will be required. But if a single format mediates the data exchange, then the target database will only have to map from the canonical format for the data in the message into its own proprietary format.
Figure 1 shows a point-to-point architecture for the messaging layer. One message leaves X, passes through messaging nodes (1) - (3), and arrives at Z. Another message leaves Y, passes through messaging nodes (4) and (5), and also arrives at Z.
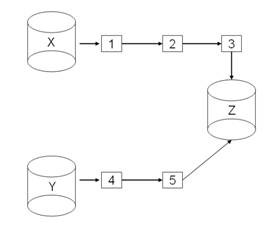
Figure 1. Point-to-point messaging
If the formats that X and Z have for this data are different, then code must map the data from X's format into Z's format. If the same message content is sent to Z from a different source, say Y, and Y's format is not identical to the format used by either X or Z, then new code must be written to map the data from Y's format into Z's format, and so on for every message sent from a source to a target database.
Hub-and-Spoke Messaging
Figure 2 shows a hub-and-spoke architecture for the messaging layer. The message leaves X, passes through messaging nodes (1) -- (3), and arrives at the hub database W. If the format that X uses for the data in the message is not identical to the canonical format for that data, then the data in the message must be mapped into canonical format before the data is stored in W.
After being stored in W, the message is reconstituted and sent on, via nodes (6) and (7), to its target Z. If the same message is sent from Y, there is another translation from Y's format into W's format, but the same code that maps the message into Z's format will work no matter which source database created the message.
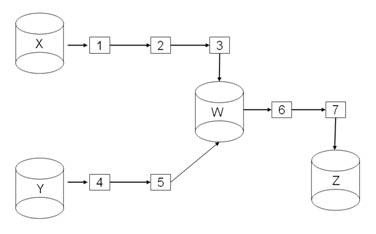
Figure 2. Hub-and-spoke messaging
As a physical database, W decouples source and target databases. It makes X, Y, and Z independent of one another as far as the different formatting of message content is concerned. X and Y may be radically modified, or even completely replaced, and Z will remain unaffected, just as long as the modifications to -- or replacements -- for X and Y continue to support the messages which they send to W.
X and Y are sources of zero or more messages that supply data to W. Those messages continually update the contents of W. When Z wants data, it obtains it from W, not from X or Y. This supports the ability, across a system of data-sharing databases, for any database to pull the data it wants from a shared repository. If instead the communication between a source and target database, say X and Z, is a push from X to Z, then X must send its data to W as a store-and-forward message, not just as a "store" message.
The data model for W is the EDM. The schemas used by W to store data define the formats for all data exchange messages received by all target databases. Those schemas instantiate the canonical message model for the system of inter-communicating databases.
If the whole point of having W is to facilitate messages among a set of databases, then why bother storing the contents of those messages in an intermediate database? Why not just drop the "store" function altogether? The answer is that the "store" function in any "store-and-forward" transmission exists to allow the transmission to be asynchronous. However, if messages between databases must be transmitted asynchronously, this does not mean that application developers must construct and manage a hub database. Commercial software that facilitates asynchronous messaging is readily available.
We can envision the hub database in Figure 2 fading away, in which case the step from (3) to W to (6) (in this case) is replaced by a direct step from (3) to (6), and the translation of X's data into canonical format can take place at any point along the transmission (in general, the earlier the better). Since W no longer physically exists, this diagram then becomes equivalent to Figure 1.
What is important is the translation into canonical format, not the storing of that mapped data in a physical database. As Malcolm Chisholm put it: "the major use case for an enterprise data model today is not for instantiating databases, but to facilitate messaging."
A Look Ahead
In Part 3, I will explain why this way of using an EDM does not achieve the same results that would be achieved by using the EDM to "instantiate databases," and thus that both of what Chisholm calls "use cases" for the EDM are still important. Specifically, I will show that if an EDM is used only to facilitate messaging, then the problem of semantic inconsistencies among databases will remain unsolved, and the objective of semantic interoperability across those databases will remain unachieved.
- - -
- - -

Tom Johnston has a doctorate in Philosophy, with a concentration in logic, semantics, and ontology. He has worked with business IT for over three decades and, in the latter half of his career, as a consultant for over a dozen major corporations. He is the author of nearly 100 articles in IT journals and is the co-author of
Managing Time in Relational Databases (Morgan-Kaufmann, 2010).
Information on the Asserted Versioning Framework, the bitemporal data management software offered by Tom's company, is available
here.
Tom offers seminars on the management of temporal data at client sites that utilize client data
issues to illustrate important temporal concepts. You can contact the author at
[email protected].