News
Google Gives Enterprises More Options for Working with Big Data in the Cloud
Hadoop connectors are now available for Google Cloud Storage, BigQuery and Cloud Datastore.
Enterprises using the Google Cloud Platform for working with Big Data in Hadoop can now use other file systems thanks to two new connectors released this week.
Google released BigQuery and Cloud Datastore connectors to give developers more options for working with Hadoop on Google's cloud in addition to the existing Cloud Storage connector.
BigQuery provides SQL-like queries against Big Data stores, while Cloud Datastore is a managed service that implements NoSQL-like queries. Cloud Storage is a RESTful Infrastructure as a Service (IaaS) storage service that can store massive amounts of data in objects of up to 5TiB in size in buckets with unique keys. The Cloud Storage connector lets users run MapReduce jobs against Hadoop data using the Cloud Storage file system. Google cloud developers wanting to work with Hadoop clusters had the option of using the Cloud Storage file system or the Hadoop Distributed File System (HDFS). While HDFS is the default file system for using Apache Hadoop, Google recommended using Cloud Storage as the default file system for working with Hadoop clusters.
"These three connectors allow you to directly access data stored in Google Cloud Platform's storage services from Hadoop and other Big Data open source software that use Hadoop IO abstractions," Google said in a blog post. "As a result, your valuable data is available simultaneously to multiple Big Data clusters and other services, without duplications. This should dramatically simplify the operational model for your Big Data processing on Google Cloud Platform."
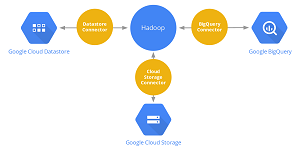 [Click on image for larger view.]
The Google Cloud Platform (source: Google Cloud Platform Blog)
[Click on image for larger view.]
The Google Cloud Platform (source: Google Cloud Platform Blog)
Google is providing MapReduce code samples to developers who want to get started using the BigQuery connector, using the Datastore connector and using the latter for reading data and the former for publishing results.
About the Author
David Ramel is an editor and writer at Converge 360.