News
VoltDB Targets Fast NewSQL Big Data Development
NewSQL company VoltDB Inc. updated its namesake in-memory, scale-out database for faster real-time analyics on streaming data.
The latest version features expanded integration with primary Big Data ecosystem component Apache Hadoop, along with several other improvements.
A NewSQL database is described on Wikipedia as "a class of modern relational database management systems (RDBMS) that seek to provide the same scalable performance of NoSQL systems for online transaction processing (OLTP) read-write workloads while still maintaining the ACID guarantees of a traditional database system."
But when those OLTP workloads scale out to Big Data dimensions, they start to resemble streaming applications, said VoltDB's John Piekos in a blog post yesterday.
"Because traditional databases historically haven't been fast enough, developers have been forced to go to great effort to capture and process fast data -- they build complex multi-tier systems often involving a handful of tools typically utilizing a dozen or more servers," Piekos said. "Developers often call these applications streaming applications, or, when combining Big Data and Fast Data, Lambda Architecture applications. Here at VoltDB, we call them VoltDB Database Applications."
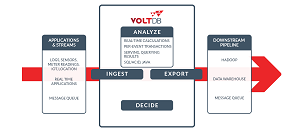 [Click on image for larger view.]
VoltDB facilitates real-time SQL analytics against fast streams of data (source: VoltDB)
[Click on image for larger view.]
VoltDB facilitates real-time SQL analytics against fast streams of data (source: VoltDB)
Developing those applications is easier with the new VoltDB 5.0, the company said in a statement, as it seeks to address the formidable task of creating "fast data applications that simultaneously extract intelligence, do real-time analytics, provide insight and take action in real time on huge volumes of streaming data."
Noting that analysts have proclaimed 2015 as "the year of Hadoop," VoltDB touted new support for the Hadoop ecosystem, including new connectors to export data to the Hadoop Distributed File System (HDFS), Kafka, RabbitMQ and more.
It also comes with new bulk data import options -- including Hadoop Output Format -- and the browser-based VoltDB Management Center for configuration and database monitoring.
"VoltDB v5.0 offers a host of new integrations, all designed to help you ingest streaming data, process it within VoltDB, and, once the data is no longer immediately valuable, export data seamlessly to a historical data warehouse," summarized Piekos.
Other features in the new version include beefed-up SQL support, the capability to define timeout limits for queries and capped collections for automatically deleting aged-out data.
"Developers are in need of better tools with which to develop fast data streaming applications with real-time analytics and decision making across industries," said CEO Bruce Reading. "As the popularity and adoption for Hadoop continues to surge, there is an increased need for integration between fast and Big Data so developers can focus on the applications and not the infrastructure. Version 5.0 meets that demand."
About the Author
David Ramel is an editor and writer at Converge 360.